Welke impact heeft
het nieuwe webtijdperk op onze informatie- en
kennisprocessen? Hoe zoeken, bewerken, creëren en
verspreiden we informatie en kennis gebruikmakend van de
stortvloed aan ‘sociale’ toepassingen die het nieuwe web ons
biedt? En wat zijn daarvan de gevolgen voor de informatie en
kennis zelf?
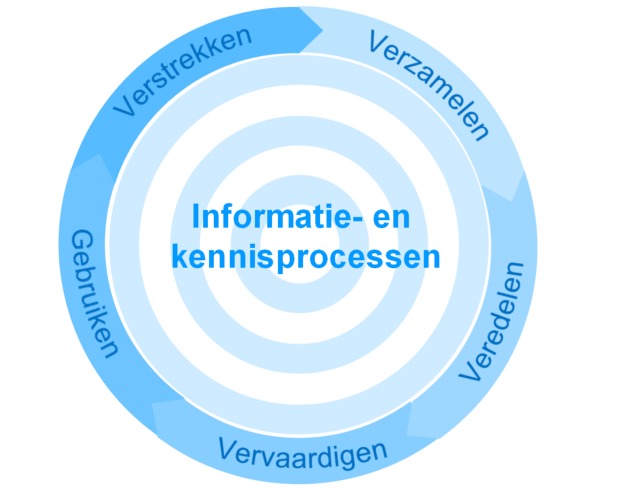
Laten we beginnen
bij de basis. De meest elementaire
informatie- en kennisprocessen zijn te verdelen in een
aantal stappen: verzamelen, veredelen, vervaardigen,
gebruiken en tenslotte verstrekken. Deze stappen grijpen op
elkaar in en voegen steeds waarde toe, vandaar dat vaak
gesproken worden over informatie- en kenniswaardeketens.
Zoals bekend heeft
de eerste golf van digitalisering de afgelopen twintig tot
dertig jaar veel veranderd. In de fase die we hier Web 1.0
hebben genoemd is het internet veranderd in een enorme
digitale bibliotheek. Vooral het verzamelen van informatie-
en kennis is daardoor volledig overgenomen door zoekmachines
zoals Google. Traditionele schriftelijk bronnen worden in
hoog tempo op internet gezet om -al dan niet tegen betaling-
ontsloten te kunnen worden. De professionele content
leveranciers zoals uitgeverijen en mediabedrijven domineren
het internet.
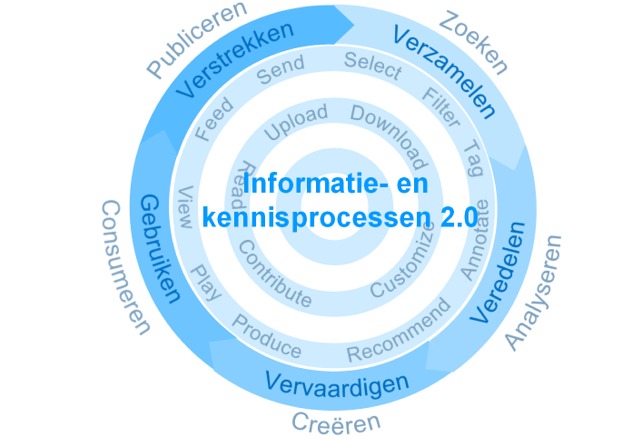
Zoals we gezien
hebben is het internet in een tweede fase beland. In het Web
2.0 werd de user generated content is minstens even
belangrijk geworden als de professionele content. Het
gebruik van sociale netwerken om deze content te
delen en te verrijken neemt een grote vlucht. In
onderstaande figuur is weergegeven welke enorme invloed dat
heeft gehad op informatie- en kennisprocessen.
Zoeken 2.0 -
Het zoeken van nieuws en andere informatiebronnen via
zoekmachines blijft onverminderd belangrijk. De kwaliteit
van de zoekmachines zal verder toenemen en de omvang van de
content op internet navenant. Deze wijze van informatie
verzamelen wordt echter aangevuld door een nieuw mechanisme
wat we kunnen omschrijven als ‘van halen naar brengen’.
Naast de zoekmachine om informatie te zoeken (pull) heeft de
gebruiker de mogelijkheden via
abonnementen op RSS-feeds informatie automatisch te
laten brengen (push). Op het moment dat er een nieuwe
bericht op een blogs of andere website verschijnt ‘pusht’ de
feed deze naar de ontvanger. Via verfijnde
toepassingen kan de men deze informatie nog verder
automatisch selecteren, filteren en voorbewerken.
Analyseren 2.0
- Het nieuwe web is interactief. Statische een-weg
publicaties worden vervangen door dynamische twee-weg
conversaties waarin gebruikers commentaar leveren,
verwijzingen toevoegen en
sociaal bookmarken. De webcontent en weblinks worden
door gebruikers ‘ge-tagd’ (van kenmerken voorzien) en
geannoteerd. In feite ontstaat er op de oorspronkelijke
content een nieuwe laag informatie over de wijze waarop
andere gebruikers deze informatie interpreteren en verwerken
. De content van het web 2.0 is in feite een permanent
zichzelf verrijkende brij van oorspronkelijk geplaatste
informatie, meta-informatie zoals verwijzingen en dynamische
gebruiks- en verwerkingsinformatie (wat is populair, veel
bekeken, hoog gewaardeerd). Verwerken en analyseren van
informatie vind in het nieuwe webtijdperk plaats binnen
sociale netwerken en veranderd zo van een solistische en
vaak lastige processtap, in een creatief
samenwerkingsproces.
Creëren 2.0
- Samenwerken is ook het sleutelwoord bij het creëren van
nieuwe content. In
wiki’s draait het om het gezamenlijk creëren,
becommentariëren en verbeteren van nieuwe informatie en
kennis. Met Wikipedia als grootste voorbeeld, maar ook bij
alle andere wikivarianten waarbij onderwijs en educatie
veelal centraal staan. Ook het vervaardigen van nieuwe
content door het mengen en verrijken van bestaande content
wordt in het nieuwe webtijdperk steeds eenvoudiger. Het
mengen van video’s en presentaties in tekst, het maken van
screencasts
(opnames van het computer scherm), het
professioneel
publiceren van content als papieren boek of als
digitaal leesbare
pdf-uitgave. De mogelijkheden zijn eindeloos en voor de
meeste eindgebruikers relatief eenvoudig toe te passen. Deze
lijst zal de komende jaren alleen nog maar groeien door de
mogelijkheden die
mashups bieden. We noemden al het koppelen van
geografische kaartmateriaal en het automatisch verzamelen
van gelijksoortige informatie.
Consumeren 2.0
- Hoe vreemd het in eerste instantie ook moge klinken, maar
het gebruiken, afspelen, lezen en gebruiken van content is
op het nieuwe web is een zeer belangrijkste stap in het
nieuwe kennis- en informatieproces. Toepassingen als Amazon
en Bol.com houden voorkeuren van gebruikers bij. Adviezen
als: ‘kopers van dit boek kochten ook” en “als in dit boek
koopt bent u wellicht geïnteresseerd in” zijn gebaseerd op
verfijnde gebruikersprofielen waarin surfgedrag en
koopgedrag minitueus worden bijgehouden. Dezelfde profielen
worden ook -bijvoorbeeld door Google- van alle activiteiten
van gebruikers op het web bijgehouden: welke webpagina, hoe
lang, welke zoekopdrachten, welke clicks, hoe laat etc. Met
deze gebruikersinformatie worden zoekmachines gevoed zodat
de zoekopdrachten van andere gebruikers effectiever kunnen
afhandelen.
Publiceren 2.0
-
Bloggen,
microbloggen, het bijdragen aan een
wiki, het uploaden van foto’s en video’s, presentaties,
boeken. De mogelijkheden om te digitaal en schriftelijk
publiceren zijn schier oneindig en erg eenvoudig. De eenvoud
van het publiceren enerzijds en de massaliteit van het
informatie aanbod anderzijds doet het publicatieproces in
een web 2.0 van karakter veranderen. Het gaat niet zozeer
meer om de vraag hoe te publiceren maar om de vraag hoe
gevonden te worden. Bijvoorbeeld door RSS-feeds toe te
voegen, speciale gadgets aan te bieden voor
informatieontsluiting of door de inhoud voor zoekmachines te
optimaliseren.